At the risk of sounding like a “linguistic prescriptivist,” as one commenter on Reddit responded to a post I made on my Subreddit (r/VibingwithAI) titled “What it means to be Vibe Coding needs refining, if not redefinition,” I suggest we should refine, if not actually redefine, what it means to be Vibe Coding.
Don’t judge me for upvoting their comment; I had to give it to the commenter. It really cracked me up. But it didn’t change my position.
At the very least, we should be on the same page about what Vibe Coding actually is, despite the dismissive attitude it often encounters from traditional developers.
I know, I know, I have been hammering this for a while, but just yesterday I watched a talk by Kitze at the recent AI Engineer Code Summit, and it triggered the mantra drumming back in my head.
It was not like any other talk you find on Vibe Coding.
First, it was packed with funny jabs, slide after slide. It will make you laugh while sprinkling serious undertones that are hard to miss, even amidst the laughter.
Secondly, he highlighted what I believe are the most essential guardrails to have in place when Vibe Coding, whether you are a non-techie entering the world of AI-assisted development, a complete newbie, or a traditional developer with coding experience.
The bottom line is we should establish clear guidelines for what Vibe Coding entails, beyond simply repeating the “giving in to the vibes” mantra.
Guardrailing the Definition: What Vibe Coding Is (and Isn’t)
As Simon Willison perfectly captured in his post“Not all AI-assisted programming is vibe coding (but vibe coding rocks),” the definition of Vibe Coding, as Karpathy initially framed it, is already escaping its original intent.
It is all over the place. I think that is why most traditional developers are sceptical about building with AI altogether.
What is more worrying is how Vibe Coding is increasingly framed as “just building with vibes,” as if no forethought is required before the first line of code is generated, as if writing code has been the bottleneck of software development all along.
No, writing code has never been the bottleneck. (Pedro Tavareλ captured this succinctly in this blog post.)
But if you lack clarity on how your product is built, the tech stack involved, and the purpose of each component underpinning your build, you are not making deliberate design or architectural choices.
Instead, you are accepting whatever the coding agent simulates for you by adopting a generic developer role implied by the statistical patterns of the fine-tuning data of the models powering it, rather than working from a shared picture of the build that should already be clear to both you and the LLM.
This is where misconceptions about Vibe Coding start to form.
Treating it as a shortcut to shipping products without taking responsibility for the technical debt that silently builds up from logical errors, potential security loopholes, impractical usability choices, and dependency compromises that eventually come back to bite you or the traditional developer that will inherit your vibe-coded project.
As I mentioned, having a clear enough definition of what Vibe Coding entails is the minimum we can do to advance this craft, as millions embrace the new era of building with AI, now that English has become the most popular programming language.
As the team at Cognition, the company behind Devin and recently Windsurf, captured the state we are in brutally in the following lines:
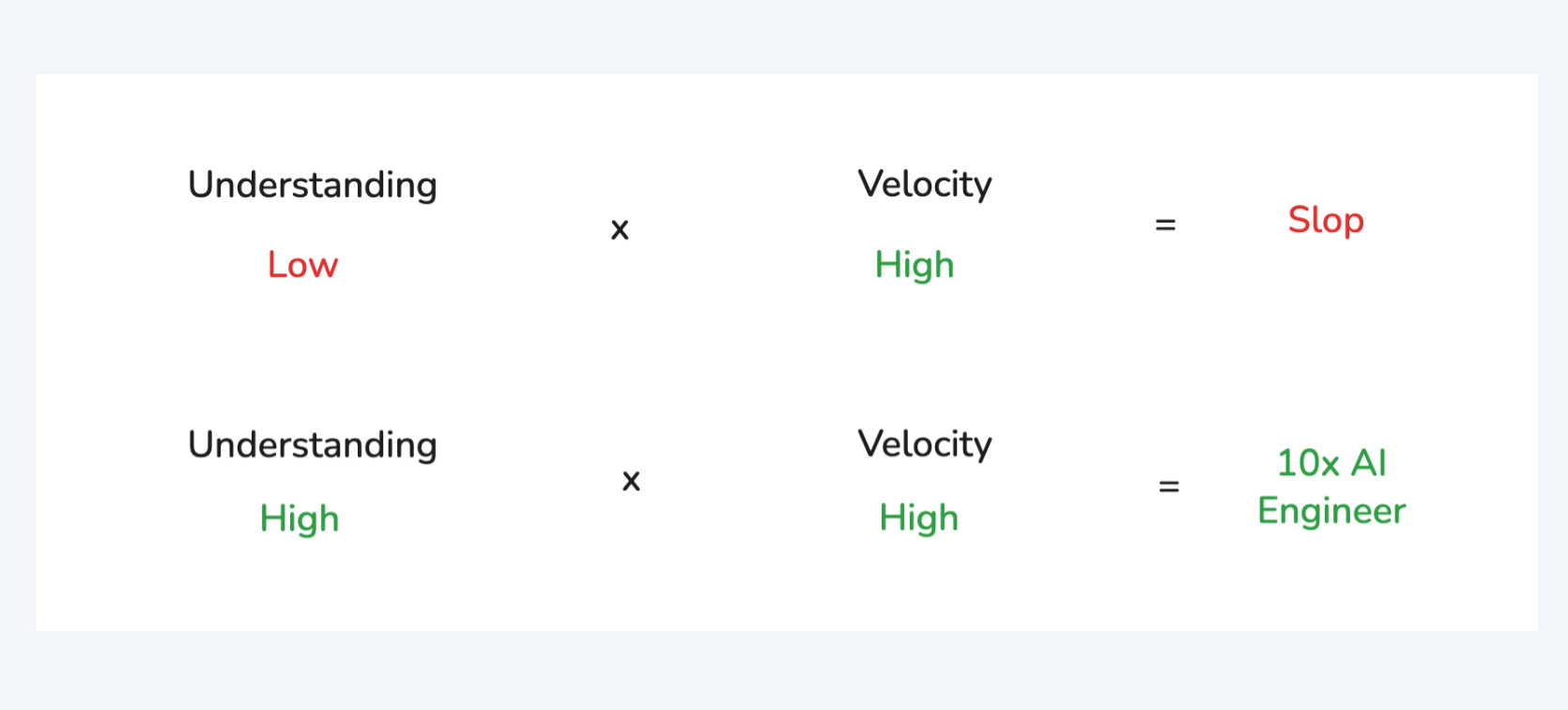
We feel that the popular usage of “vibe coding” has strayed far from the original intent, into a blanket endorsement of plowing through any and all AI generated code slop. If you look at the difference between the most productive vs the problematic AI-assisted coders, the productive ones can surf the vibes of code that they understand well, whereas people get into trouble when the code they generate and maintain starts to outstrip their ability to understand it.
Guardrails as Coordination: The Shared Picture Problem
Vibe Coding breaks down when you and the LLM powering the coding agents of your chosen CodeGen platform or AI-assisted coding tool no longer have a shared picture of the build—the product you are using AI to help you create.
That is the part that often gets missed.
Everyone is trying to wing it.
Treating LLMs like slot machines.
Among the countless memes on Vibe Coding, Kitze selected one that compares irresponsible Vibe Coding to gambling at a casino.
Relying solely on “vibes” without the necessary skillset to navigate the code that the coding agents generate for them, code that“outstrips their ability to understand it”.
If you do not communicate your requirements clearly, the LLM has no concrete picture of your build and instead simulates a generic version based on patterns it has seen before during fine-tuning—effectively adopting an implied role shaped by the statistics of that data.
You throw token credits at every turn, chase the successive win, and mistake motion for progress while time and token credits quietly drain away.
Occasional successes masquerading as a reinforcement of poor process.
Refined UIs at every iteration, featuring components you have seen and liked elsewhere.
Code files multiply. Mostly, lines of code get clumped into a single file.
Meanwhile, you and the LLM are already misaligned.
You no longer can justify why something exists, what depends on it, or what will break if you touch it. You are reacting to what shows up instead of shaping the build.
An earlier iteration of Vibe Coding assumed something important: review.
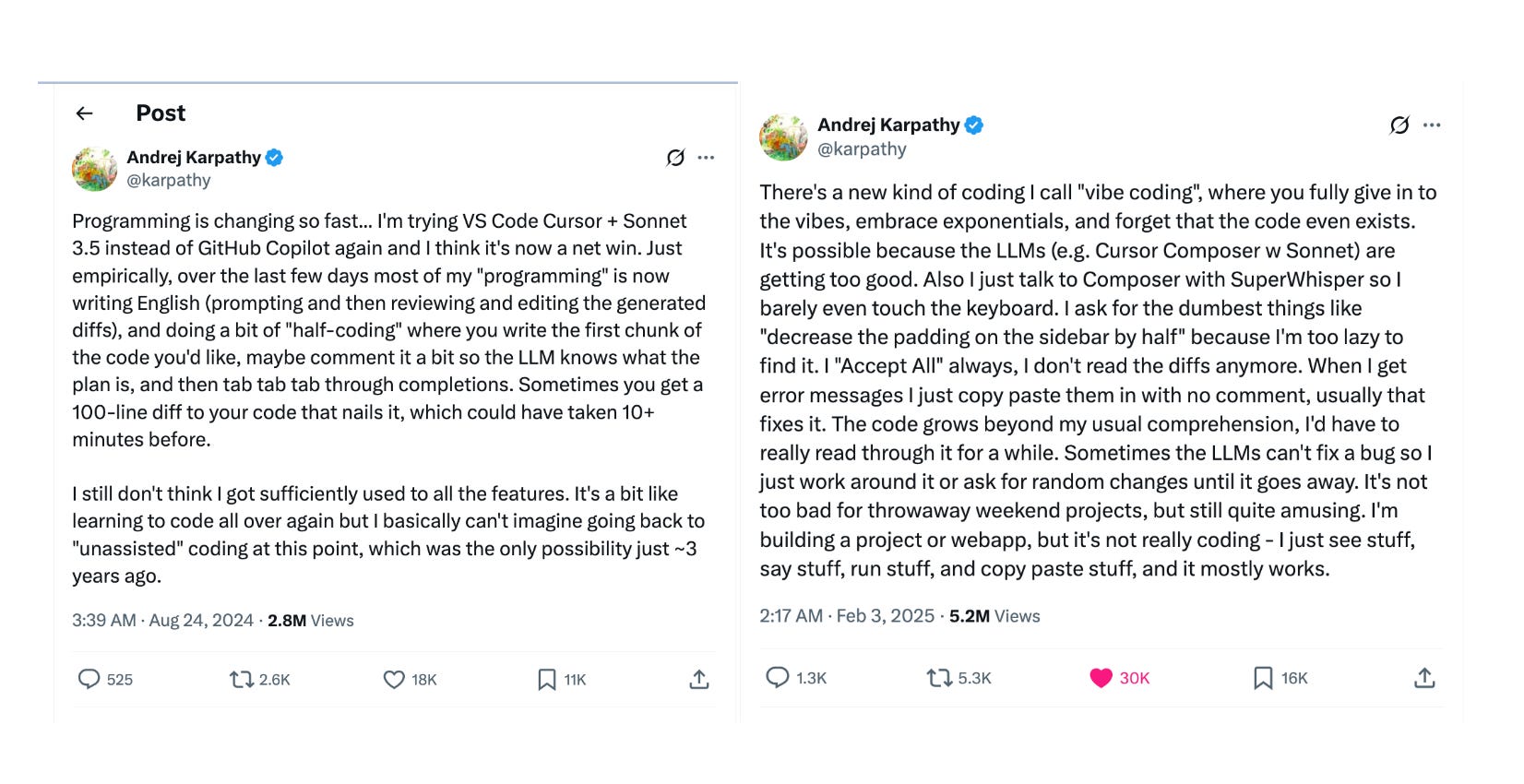
We have been riding the Vibe Coding train so fast that we have almost forgotten the earlier iteration Karpathy described: “half-coding.”
In half-coding, intent was expressed in English, similar to Vibe Coding, followed by generated diffs, which were then reviewed and edited. This is more like the current definition of what is called AI-assisted programming.
That step—review—ensured a shared understanding of what was being produced.
You needed to speak Dev, have architectural awareness of how modern software products are wired, and gain coding experience.
As the models improved, that assumption quietly disappeared.
Seven months after half-coding was introduced, Vibe Coding took over.
Within Seven Months
LLMs have continued to improve in code-reasoning abilities, but maintaining a shared picture remains vital.
You are the one who should define the grounding for your build-to-be.
After all, we are still dealing with what Pablo Enoc aptly described as “the equivalent of a lexical bingo machine”.
Without a shared picture of your build-to-be with the LLMs powering the coding agents, Vibe Coding stops being a creative workflow and becomes an improvisation exercise—where agents rush to fulfil a wishlist, while you lose track of the build you thought you were co-creating.
Guardrails as Risk Containment: When the Bill Comes Due
This is where misconceptions about Vibe Coding start to compound.
When you treat it as a shortcut to shipping products without owning what is being generated under the hood, you are not skipping work.
You are deferring to (most probably) traditional developers, who are eager to profit from your non-techie missteps.
Logical errors slip in quietly.
Security loopholes remain invisible until they are not.
Usability (how the product behaves during user interactions) decisions are accidentally locked in on the fly.
Dependencies pile up without you having any idea why they were added in the first place.
None of this feels consequential while you are in the flow. Vibing.
It only shows up later, when something breaks, and you are no longer sure what changed, what relies on what, or which part of the system is actually responsible for the one or many errors that pop up here and there.
This is usually the moment when someone else gets involved.
Mostly traditional developers step in to untangle the underlying wiring that evolved without architectural clarity, built by agents that were never given foundational guardrails, so they went off and did what is statistically probable based on the data used to fine-tune them into a code-generating agent.
This isn't about the models.
We understand their true nature.
They are inherently non-deterministic.
Instead, it concerns approaching Vibe Coding recklessly without any pre-defined safeguards.
As more products are built with code generated by LLM-powered coding agents, these issues stop being isolated to individual side projects.
Security blind spots do not stay contained.
They propagate.
Into platforms.
Into the broader ecosystem where those products will operate.
The Internet.
That is a nightmare for another conversation.
Guardrails as Discipline: The Skills Vibe Coding Still Demands
Those who have been practicing it since its inception in February 2025 have made many recommendations for how Vibe Coding should be carried out.
I have been emphasizing my version of foundational literacies that non-techies venturing into the world of building with AI should adhere to since I started this Substack.
Vibe Coding is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Speaking Dev in the lingo of traditional developers and having a mental model of how modern software products are wired.
You now see different versions of “obvious advice” echoed across the internet, from people who have been in the trenches building with AI, each approaching Vibe Coding from a slightly different angle, but all circling the same underlying discipline.
Kitze’s talk wasn’t so much about introducing new ideas as it was a reminder of how easily we tend to forget them.
Kitze’s perspective is one of many.
Apart from the last one, which I find overwhelming for a non-techie who is entirely new to this world of LLM-powered AI, the advice is worth considering.
Trust me when I say this: even those of us who have experienced the evolution of the web tech stack over the past twenty years are feeling it.
Model capabilities are advancing rapidly, and CodeGen platforms and AI-assisted coding tools are responding by introducing entirely new layers of abstraction into the development process.
Keeping track of everything is equally overwhelming for both non-techies and traditional developers alike.
The fact that models are improving rapidly, however, does not eliminate the need for a disciplined approach that is not based solely on “vibes”.
After all, you can’t “surf the vibes of code” that you do not understand well.
Some of these skills originate from traditional software development practices that Vibe Coding Still Demands.
Effective Vibe Coding still requires understanding the model’s limits, the agent’s capabilities, the context boundaries, and the constraints on how coding agents act.
Oh, not to forget the number of tokens the task involves, from planning to integrating external web services and preparing deployment configurations.
Token credit also factors in (Can’t stop wishing for an outcome-based pricing model for coding agents’ usage. Is it too late to wish for that this Christmas?).
Returning to reality, though, without foundational literacies, what looks like creative freedom turns into chaos.
Half-working features.
Features that break when you fix something else.
Token credits are burned with hardly anything to show for their disposal.
And technical debt is quietly accumulating in the background, awaiting the moment the product shifts from dev mode to production mode.
Guardrailing the Space Where Vibe Coding Works: Scope and Boundaries
There is a time and place for Vibe Coding.
Kitze was clear about this, and I couldn’t agree more.
One-off scripts.
Software for one.
Simple features.
These are situations where speed matters more than long-term structure, and where the cost of being wrong is contained.
In those spaces, giving “in to the vibes” makes sense.
You are not building infrastructure.
You are not laying foundations.
You are exploring, experimenting, and moving fast with an idea that does not need to survive long-term scrutiny.
As models continue to improve, this boundary will likely expand.
In the last 11 months since the conception of Vibe Coding, we have seen models evolve from “no, they will not be able to do that” to models managing long-running tasks and even demonstrating clarity across context windows while executing implementations in parallel from a single unified orchestration platform.
All of this will make vibe-driven workflows viable for more use cases than they are today.
But the principle does not change.
The longer a product is intended to last, the more people rely on it, and the greater the risk involved, the less room there is to “give in to the vibes.”
At that point, vibes without guardrails stop being creative freedom and start becoming a liability.
So What Would Responsible Vibe Coding Look Like?
Responsible Vibe Coding does not mean slowing down or giving up the advantages of leaning on models when building with AI.
It means knowing when to lean into speed and when to pause and ask harder questions.
It means starting with a clear picture of what you are trying to build, not trusting that clarity will magically emerge from a long chat thread.
It involves reviewing your work before rolling, ensuring you understand what was produced well enough to explain it yourself, and avoiding the temptation to consider progress as simply whatever appears on the screen.
Be cautious that an inherently non-deterministic system drives coding agents.
So, outsourcing judgment is a no-go.
As models advance and coding agents become more capable, the desire to yield to the authority of the LLMs will only increase.
The CodeGen platforms, through vertical integration, and the AI-assisted coding tools, with built-in guardrails, are trying to abstract most of the process of building with AI.
That is an exciting and welcome improvement, especially for those who have never had technical experience.
The latest versions of their respective models are expected to minimize human intervention during debugging (finding and fixing errors in code), support longer autonomous debugging cycles, and enable end-to-end delivery of fixes.
In most cases, the cost of ignoring the review of what the coding agents generate often does not become immediately apparent. Yes, syntactic mistakes would be visible and relatively easy for the models to catch. Subtle logical errors, however, are the kind of errors the models will struggle to identify. Your lack of clarity about the problem you are trying to solve causes logical errors.
After all, the models are only improving at debugging code, not at fixing the mental clarity you never had as you set out to build your product, about how your product should be wired using which components.
It will surface later, when the product needs an upgrade, to scale, or to accommodate real-world streams of users with real-world usage scenarios defined by different behavioral patterns and form factors.
Vibe Coding is here to stay.
That debate has been settled.
End of story.
But the question remains.
The question is whether it continues to be a creative way to build with AI, or if it quietly leads to a flood of Vibeslop.
It doesn’t matter how smart the models get or how capable they are at tool use, as long as the non-deterministic nature of LLMs is not replaced with a new paradigm, the guardrails will remain to see another day.
It is not the model that keeps your build from derailing while Vibe Coding.
It is the guardrails you bring with you when you start.
It is the guardrails you bring to control the models’ unpredictable nature.